
Introduction:
Globalization has brought countries together in more ways than ever before. Consumers, corporations and governments alike, now have generally unfettered access to innovations, markets, products and services. While the benefits associated with globalization are many, it also brings associated risks, as we have seen with the recent SARS-COV2 virus. Infectious disease specialists have been raising the alarm about the need for an effective and uniform response to these threats, due to the speed at which an infectious disease could spread as a result of our global connectedness.
COVID-19 (the disease caused by the SARS-COV2 virus) has completely taken over our lives, resulting in a material effect in the lives of countless global citizens. The question at the top of everyone’s mind is “How do we adjust to this new normal?”
Specifically, what can we learn about patterns and prevention as we analyze how an infectious disease like COVID-19 migrates and assess how industries are impacted by its spread? This understanding can help inform public health directives that aim to control the migration of the disease, while at the same time alleviating resulting strains on the economy.
Study Objectives:
To develop a better understanding of these patterns, our Data Science teams at Inspired Intellect and WorldLink initiated an R&D project with the hypothesis that advanced analytics could uncover insights to address the above questions. We were also looking for pragmatic applications for deploying our findings to help our clients understand how their businesses would need to adapt to survive in the rapidly evolving new normal.
We focused our research efforts into 4 distinct tracks:
- Creating a data lake of information as a foundational pillar for our research
- Collating and categorizing experimental treatments, therapeutics and vaccine research into a semantic search-driven library of knowledge to support frontline healthcare workers and medical practitioners as they keep up with trending research in these domains (here)
- Social listening and associated unstructured text analysis to identify and surface trending topics and concerns people were talking about
- Machine learning and insight generation to identify the factors influencing the spread of virus to predict the waxing and waning of virus epicenters over time.
This article is Part 1 of a 2-part blog series focused on the 4th track above: Machine learning and insight generation. This blog series is focused on answering the following questions:
- Why are certain counties/cities more affected than others?
- Why is there variation in mortality rates among the most infected counties?
- What are the underlying patterns and factors for virus spread and mortality?
In this first installment, we will provide recommendations on how to mitigate the spread of infectious diseases, based on our working using county-level data and machine learning techniques. In Part 2, we will explore model data, features and insights.
We feel that a data-driven scientific approach can help answer these questions and, more importantly, inform decision making for a range of stakeholders:
- Policy Makers: Have sufficient measures been taken to ensure that the infection spread can be controlled? If not, how do we mitigate the risks?
- Business Owners: Is my business a potential contributing vector to the spread of the virus? What measures should we consider implementing relative to operating the business in a manner that is safe for employees and customers?
- Individuals: What measures can we as individuals take to help stem the spread of the virus?
Editor’s Note: This blog post was authored to highlight Inspired Intellect’s perspective on how the latest advanced analytics techniques could examine driving factors behind the COVID-19 pandemic and garner recommendations to inform officials in their policy responses. To do this, I co-authored this blog with my colleague, Prashanth Nayak, who serves as a Senior Data Scientist for our partner organization, WorldLink. There were several others across Inspired Intellect involved in the data sourcing and model development necessary to deliver these insights related to the pandemic and potential actions to mitigate its impact.
Our Findings: Guidelines for a Pandemic Playbook
To garner our final recommendations, the Inspired Intellect team ran several machine learning models across a broad intersection of data sets at the local, regional and national. The results were surprising and represent actionable steps that stakeholders can follow when seeking to mitigate the negative impact of a pandemic.
Specifically, several learnings from our models serve as primary considerations in the context of developing a pandemic response playbook.
- The Need for Data Granularity and Capture Standards: The data we employed was captured at the county-level and released for public consumption through the COVID-19 Tracking Project. In the early days of the project’s data reporting, it was clear that data capture standards were not mandated across states and counties – which restricted what was possible via machine learning. Secondly, as was evident in the public domain, it also handicapped public health policy decision makers. Finally, data richness was a constant challenge during this research study. The fact that externally sourced overlays of census track demographic statistics surfaced to the top of our important features, demonstrates the value of capturing demographic, psychographic, socio-economic as well as pre-existing/underlying health conditions data at the case-level of detail. Together with a robust contact tracing methodology, these data can provide valuable insights that will permit balancing containment measures with keeping the nation’s economy afloat during a pandemic.
- A Positive Correlation with Increased Local Decision-Making Autonomy: Our models implicitly demonstrate that a local county-level (or perhaps even city-level) autonomy with public health policies may be more effective at preventing the spread and, as some of our key independent variables have illustrated, a county may also need the cooperation of neighboring counties (or cities), in order to succeed. It is true that a broad-brush approach may be appropriate in the initial weeks to give first responders and public health policy makers an opportunity to organize, determine action plans and deploy resources. As we have seen, however, if that time is not adequately utilized to mechanize a credible pandemic response, it is likely that the county will see infection rates escalate and the increased likelihood of a shelter-in-place/shutdown order from authorities. Naturally, this has an adverse effect on the health of its people and will eventually cause a drag on the economy.
- The Importance of State and Federal Support: Surprisingly significant independent variables, such as a county’s proximity to major airports, illustrate that state and federal support may be better directed at containing international and interstate travel to mitigate the spread. Additionally, we saw that state and federal support was highly effective in mitigating the spread of the disease when it was deployed to ensure adequate access to healthcare facilities. This materialized as ICU beds in our models, but it could easily be extrapolated to everything else that is needed to keep hospitals and ICU facilities operational (from personal protective equipment, oxygen and ventilator equipment to funding virus testing, treatments and vaccine research). Lastly, state and federal resources should be directed towards defining data collection standards, providing recommendations and best practices for the analysis of the collected data as local county (or city) administrators may not have the resources to recognize patterns beyond their local geographies.
- Addressing the Health-Equity Gap: The state of health equity has emerged as one of the most revealing aspects of COVID-19, defined as the ability for citizens across different social stratifications to receive equal healthcare. While our models indirectly captured its effect through county-level demographic proxies, population density and net migration data, it nevertheless brings to the forefront the health-risk faced by the underprivileged. Not only are the populace in these geographies more prone to exhibiting underlying health conditions because of occupational or lifestyle characteristics, but they often also do not have access to adequate medical care or the financial means to avail of it, should they be infected. Based on the analysis, programs to address this socioeconomic gap with regards to healthcare access would prove as a valuable investment in slowing the spread and fatality rates associated with a pandemic.
Taken together, these points effectively capture the reasons behind the current “state of the COVID-19 battle” in the US. It is certainly not one person, one agency or one thing, but a perfect storm of unpreparedness in the context of recognizing the “who”, “what”, “why”, “when”, “where” and “how” to beat COVID-19 effectively.
Our research demonstrated how machine learning can be a powerful tool in aiding policy makers as they develop appropriate action plans to counter the threat of a pandemic. While interpreting each independent variable separately, it is easy to lose sight of the bigger picture of what the models are telling us.
Behind the Quantitative and Predictive Models That We Used:
Given the increasing volume of data related to the COVID-19 virus, we had a plethora of options as to how to construct our model. In discovering these insights, the Inspired Intellect team used the following attributes and models:
Data Attributes
- COVID-19 daily cases and deaths data for every county within the United States (US), captured and published by the New York Times between January 1, 2020 and May 31, 2020 (Coronavirus (COVID -19) data in the United States, 2020).
- Socioeconomic and health equity characteristics data such as population sizes, unemployment rate, occupation , household income , household size , ICU beds for every county within US captured (county-level socio-economic data in United States, 2019)
- Land area in square miles, population, domestic and international migration data, gender proportions, age groups for every county within US captured and published by United States Census Bureau (county-level census data in United States, 2019)
- Mobility data reporting movement of trends over time by geography, across different categories of places such as retail and recreation, groceries and pharmacies, parks, transit stations, workplaces, and residential (Google mobility data)
- Airport data: Proximity of airports for each county, importance of the airports (openflights.org and the Bureau of Transportation Statistics)
Models
- Quantitative risk score model: A risk score is assigned to each county based on the county’s rate of change in infection rates, mortality rates, and population density. This model’s purpose is to aid our clients in prepare action plans based on relevant counties.
- Infection rate machine learning model: Model predicting if a given county’s infection rate will increase from the previous week. Model also produces the drivers (feature importance) behind infection rate increase and helps analyze hotspot changes over time.
- Mortality rate machine learning model: Model predicting if a given county’s mortality rate will increase from the previous week. Model also produces the drivers (feature importance) behind mortality rate increases and helps identify vulnerable demographics.
Enabling Technologies That We Used:
It is a well-known fact that analytical models are only as good as the data that they employ. The importance of consistent data reporting standards, incremental expansion of the data assets considered, as well as periodic retraining of the models against the latest data cannot be diminished. In order to deliver such capabilities consistently, and at scale, we must acknowledge the role of a strong data management foundation.
As we began our research initiative during the early stages of the pandemic reaching US territory, we were faced with significant data challenges. As we noted earlier, COVID-19 data reporting standards were nascent, if they existed at all, and they were evolving. Consequently, acquiring data that was collected in a consistent manner across all counties was difficult, and required us to do a large amount of transforming. Another challenge we encountered was the lack of a historical audit thread of day-over-day statistics related to infections, mortalities and recoveries. Yet another hurdle centered around the fact that data formats were not consistent in the early days. Eventually, open-source initiatives such as the “COVID-19 Tracking Project” emerged, that alleviated some of our initial challenges, but even those required experience with semi/unstructured data management capabilities to extract, store and transform data within JSON files or PDF reports.
The table below summarizes our technology choices for what began as an internal R&D effort but is rapidly expanding to an offering at the request of several customers. To the opportunities presented by the latter, several other technologies present themselves as viable alternatives within our offering technology stack.
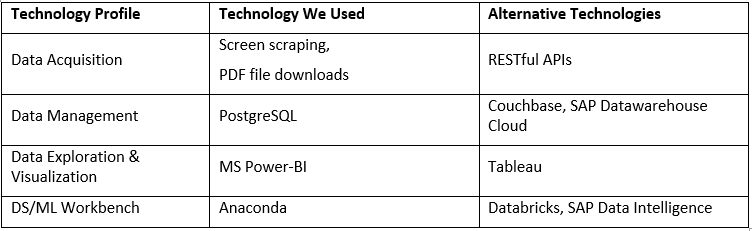
Technology choices will ultimately be guided by a variety of factors – from the most obvious, such as alignment with your enterprise architecture strategy and ease of integration with other enterprise business applications, to the less obvious, such as performance scalability of a solution that is consistently evolving over time or the flexibility to adapt to a variety of data and analytics needs as your business evolves. To ensure success in this initiative, the Inspired Intellect team relied on its vast experience in analyzing the solution landscape to align enterprise/data fit with best-in-breed tools.
Conclusion:
We discovered during our research that it is nearly impossible to earn an “A” grade while trying to mitigate the effect of a global pandemic, but that it is rather easy to earn a “B”. COVID-19 has upended the lives of numerous individuals, families, businesses, and countries, and our goal is to use the latest advanced analytics techniques to raise the floor for our global citizens and improve our chances of being successful, now and in the future of increased globalization.
Inspired Intellect is an end-to-end service provider of data management, analytics and application development. We engage through a portfolio of offerings ranging from strategic advisory and design, to development and deployment, through to sustained operations and managed services.
Inspired Intellect is part of the Adi Group. The Adi Group is a collection of companies that, collectively, advises on and implements enhanced technological capabilities for enterprises along their digital transformation journey. Members of the Adi Group include:
- WorldLink
- Inspired Intellect
- ADI Family Office
- The ADI Foundation
- Inspired Intellect’s membership in the Adi Group allows its clients access to a broader portfolio of digital transformation solutions and multiple touch points with innovation.


